Is there such a thing as a task where you would not need a cursor? Hidden in the depths of the master database are a series of stored procedures that can replace some cursors with these one-liners. Behind the scenes, cursors are still used, but they will save you tons of development time.
Traditionally if you wanted to run a DBCC CHECKTABLE on every table in a database you'd have to write an elaborate cursor like below :
create table #Result
(
tablename nvarchar(1000),
columnname nvarchar(1000),
searchvalue nvarchar(1000)
)
declare @searchstring as varchar(1000)
declare @searchscript as varchar(2000)
set @searchstring = 'Hossam'
set @searchscript =
'declare @sql as varchar(8000)
set @sql = ''select '''''''' tablename,'''''''' columnname,'''''''' value where 1=0''
select
@sql = @sql + '' union all select ''''?'''','''''' +
name + '''''',['' + name + ''] from ? where ['' + name + ''] like ''''%' + @searchstring + '%''''''
from
syscolumns
where
xtype in (175,239,231,167)
and id=object_id(''?'')
insert into #Result
Exec (@sql)
print ''search is completed on ?.'''
exec sp_msforeachtable @searchscript
select * from #Result
--drop table #Result

Wednesday, November 14, 2007
Tuesday, November 6, 2007
Microsoft Windows PowerShell and SQL Server 2005 SMO
As you probably know, Windows PowerShell is the new command shell and scripting language that provides a command line environment for interactive exploration and administration of computers. In addition, it provides an opportunity to script these commands so that we can schedule and run these scripts multiple times.
Windows PowerShell depends on .NET framework 2.0. SQL Server Management Objects, known as SMO, is an object model for SQL Server and its configuration settings. SMO-based applications use .NET Framework languages to program against this in-memory object model, rather than sending Transact-SQL (T-SQL) commands to SQL Server to do so.
In this article series, I am going to illustrate the power of Windows PowerShell in conjunction with SQL Server 2005. Part I of this series is going to illustrate how to install and use a simple PowerShell command and a simple SMO command.
Assumption
a. The machine you use already has .NET 2.0 installed b. The machine you use already has SQL Server 2005 client installed with the latest service pack Download and Install Microsoft PowerShell.
Download Microsoft PowerShell “WindowsXP-KB926139-x86-ENU.exe” from http://download.microsoft.com/
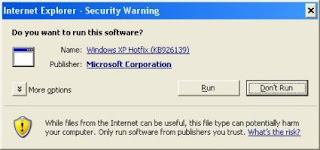
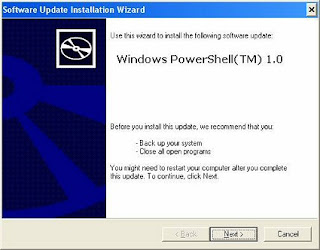
b. Install PowerShell Step 1: Double click on the “WindowsXP-KB926139-x86-ENU.exe’ executable. [Refer Fig 1.0]

Launch PowerShell
There are few ways to launch PowerShell. One method is to go to the command prompt and type the following command. [Refer Fig 1.6]
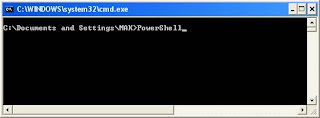
After a short pause, the PowerShell prompt appears. [Refer Fig 1.7]
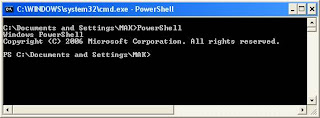
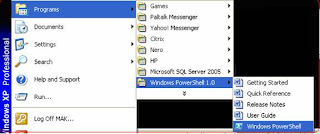
Alternatively, you can start PowerShell by selecting Programs-Windows PowerShell 1.0-Windows PowerShell. [Refer Fig 1.8]
Windows PowerShell depends on .NET framework 2.0. SQL Server Management Objects, known as SMO, is an object model for SQL Server and its configuration settings. SMO-based applications use .NET Framework languages to program against this in-memory object model, rather than sending Transact-SQL (T-SQL) commands to SQL Server to do so.
In this article series, I am going to illustrate the power of Windows PowerShell in conjunction with SQL Server 2005. Part I of this series is going to illustrate how to install and use a simple PowerShell command and a simple SMO command.
Assumption
a. The machine you use already has .NET 2.0 installed b. The machine you use already has SQL Server 2005 client installed with the latest service pack Download and Install Microsoft PowerShell.
Download Microsoft PowerShell “WindowsXP-KB926139-x86-ENU.exe” from http://download.microsoft.com/
b. Install PowerShell Step 1: Double click on the “WindowsXP-KB926139-x86-ENU.exe’ executable. [Refer Fig 1.0]

Fig 1.0



Launch PowerShell
There are few ways to launch PowerShell. One method is to go to the command prompt and type the following command. [Refer Fig 1.6]

After a short pause, the PowerShell prompt appears. [Refer Fig 1.7]

Alternatively, you can start PowerShell by selecting Programs-Windows PowerShell 1.0-Windows PowerShell. [Refer Fig 1.8]

Tuesday, October 30, 2007
Setting the default Button in ASP.NET
to set default button in ASp.net 2.0 is to easy but in asp.net 1.0 i think every one will be facing the problem i hade faced.
i try to use many ways to solve this problem and finally solve it by the below Syntax put it in your page load and replace the text name with your text on the page and the button y need to make it the default button and happy code
txt_Search.Attributes.Add("onkeydown", "if(event.which event.keyCode){if ((event.which == 13) (event.keyCode == 13)) {document.getElementById('" + Me.btn_Search.UniqueID + "').click();return false;}} else {return true}; ")
:)
i try to use many ways to solve this problem and finally solve it by the below Syntax put it in your page load and replace the text name with your text on the page and the button y need to make it the default button and happy code
txt_Search.Attributes.Add("onkeydown", "if(event.which event.keyCode){if ((event.which == 13) (event.keyCode == 13)) {document.getElementById('" + Me.btn_Search.UniqueID + "').click();return false;}} else {return true}; ")
:)
Tuesday, October 9, 2007
SQL Server 2008 New Featuers
SQL Server 2008 contains many new features and enhancements, Additional information can be found at the main SQL 2008 Microsoft page: http://www.microsoft.com/sql/2008/default.mspx. Listed below is a concise bulleted list of the SQL Server 2008 features .
- Transparent Data Encryption. The ability to encrypt an entire database.
- Backup Encryption. Executed at backup time to prevent tampering.
- External Key Management. Storing Keys separate from the data.
- Auditing. Monitoring of data access.
- Data Compression. Fact Table size reduction and improved performance.
- Resource Governor. Restrict users or groups from consuming high levels or resources.
- Hot Plug CPU. Add CPUs on the fly.
- Performance Studio. Collection of performance monitoring tools.
- Installation improvements. Disk images and service pack uninstall options.
- Dynamic Development. New ADO and Visual Studio options as well as Dot Net 3.
- Entity Data Services. Line Of Business (LOB) framework and Entity Query Language (eSQL)
- LINQ. Development query language for access multiple types of data such as SQL and XML.
- Data Synchronizing. Development of frequently disconnected applications.
- Large UDT. No size restriction on UDT.
- Dates and Times. New data types: Date, Time, Date Time Offset.
- File Stream. New data type VarBinary(Max) FileStream for managing binary data.
- Table Value Parameters. The ability to pass an entire table to a stored procedure.
- Spatial Data. Data type for storing Latitude, Longitude, and GPS entries.
- Full Text Search. Native Indexes, thesaurus as metadata, and backup ability.
- Reporting Server. Improved memory management.
- SQL Server Integration Service. Improved multiprocessor support and faster lookups.
- MERGE. TSQL command combining Insert, Update, and Delete.
- SQL Server Analysis Server. Stack improvements, faster block computations.
- SQL Server Reporting Server. Improved memory management and better rendering.
- Microsoft Office 2007. Use OFFICE as an SSRS template. SSRS to WORD
Wednesday, July 11, 2007
Monitoring Stored Procedure Usage
I was attending a SQL Server event a few weeks back when a number of DBA types were talking about new features in SQL Server 2005. One of the topics that came up was how might you monitor execution of stored procedures. One DBA said it would be nice if he had a method to identify how many times a stored procedure (SP) was executed. He was looking for some information to help fine tune his environment and the applications running in his environment. Or at least identify the processes that where run frequently so they could be reviewed by developers to determine if they could be written more efficiently. So what new features in SQL Server 2005 might be used to accomplish the monitoring of SP executions? Dynamic Management views (DMV) of course. In this article I will show you how you can use a few DMV’s to identify the most frequently run SPs of an instance of SQL Server, as well as those SPs that use the most CPU, I/O or run the longest.
Execution Statistics
It is relatively easy to identify the use count and resource usage of your SP’s, but first let me discuss how SQL Server maintains the execution statistics. The SQL Server engine keeps execution statistics for each SQL Server 2005 instance. Execution Statistics are an accumulation of execution information about what has been run since the instances has started. Each time an instance is stopped and restarted all execution statistics are reset.
Individual execution statistics for an object are tied to cached execution plans. When a SP is compiled, an execution plan is cached in memory. These cached execution plans are uniquely identified by a plan_handle. Since memory is limited, SQL Server from time to time will remove execution plans from memory, if the cached plan is not being actively used. Therefore the statistics stored for a particular SP may be for an accumulation of stats since SQL Server started, if the SP has only be compiled once. Or, it may only have statistics for the last few minutes if the SP had recently been compiled.
How to Get the Execution Count of a Stored Procedure?
To determine how many times a stored procedure in the cache has been executed you need to use a couple of DMV’s and a dynamic management function (DMF). The plan_handle for the cached plans are used to join together the DMVs and retrieve records for a DMF. To get the execution counts for each cached SPs you can run the following code:
SELECT DB_NAME(st.dbid) DBName
,OBJECT_SCHEMA_NAME(st.objectid,dbid) SchemaName
,OBJECT_NAME(st.objectid,dbid) StoredProcedure
,sum(qs.execution_count) Execution_count
FROM sys.dm_exec_cached_plans
cp join sys.dm_exec_query_stats qs on cp.plan_handle = qs.plan_handle
CROSS APPLY sys.dm_exec_sql_text(cp.plan_handle) st
where DB_NAME(st.dbid) is not null and cp.objtype = 'proc'
group by DB_NAME(st.dbid),OBJECT_SCHEMA_NAME(objectid,st.dbid),
OBJECT_NAME(objectid,st.dbid)
order by sum(qs.execution_count) desc
Here I used the plan_handle of the “sys.dm_exec_cached_plans” DMV to join with the “sys.dm_exec_query_stats” DMV to obtain the “Execution_count” value where the object type is a store procedure. The “execution_count” column of the “sys.dm_exec_query_stats” DMV identifies the number of time the cached_plan (or SP) has been executed since the last compilation of the SP. I use the plan_handle in conjunction with the CROSS APPLY operator to return the object information (DBName, SchemaName, and ObjectName) using the table-value DMF “sys.dm_exec_sql_text”. The output from this SELECT statement is ordered by the execution_count, so the SP with the most executions will be displayed first.
Determining Which SP is using the Most CPU, I/O, or has the Longest Duration.
Knowing which SPs are frequently executed is useful information, although from a performance standpoint you might like to know which SP is consuming the greatest amount of CPU resources. Or possibly you might be interested in which SP takes the longest to run, or which SP performs the most physical I/O operations. By modifying the above command, we can easily answer each one of these questions.
If you want to show the SP that consumes the most CPU resources, you can run the following TSQL command:
SELECT DB_NAME(st.dbid) DBName
,OBJECT_SCHEMA_NAME(st.objectid,dbid) SchemaName
,OBJECT_NAME(st.objectid,dbid) StoredProcedure
,sum(qs.execution_count) Execution_count
,sum(qs.total_worker_time) total_cpu_time
,sum(qs.total_worker_time) / (sum(qs.execution_count) * 1.0) avg_cpu_time
FROM sys.dm_exec_cached_plans cp join sys.dm_exec_query_stats qs on cp.plan_handle = qs.plan_handle
CROSS APPLY sys.dm_exec_sql_text(cp.plan_handle) st
where DB_NAME(st.dbid) is not null and cp.objtype = 'proc'
group by DB_NAME(st.dbid),OBJECT_SCHEMA_NAME(objectid,st.dbid), OBJECT_NAME(objectid,st.dbid)
order by sum(qs.total_worker_time) desc
The “sys.dm_exec_query_stats” view contains the column “total_worker_time”, which is the total number of microseconds that a given cached query plan has executed. Keep in mind that cached plans are sometimes removed from memory and replaced with newer ones. Therefore, the statistics for which SP has consumed the most CPU only takes into account statistics for those plans that are in the cache when this T-SQL is run.
To determine which SP has executed the most I/O requests you can run the following TSQL code:
SELECT DB_NAME(st.dbid) DBName
,OBJECT_SCHEMA_NAME(objectid,st.dbid) SchemaName
,OBJECT_NAME(objectid,st.dbid) StoredProcedure
,sum(execution_count) execution_count
,sum(qs.total_physical_reads + qs.total_logical_reads + qs.total_logical_writes) total_IO
,sum(qs.total_physical_reads + qs.total_logical_reads + qs.total_logical_writes) / sum(execution_count) avg_total_IO
,sum(qs.total_physical_reads) total_physical_reads
,sum(qs.total_physical_reads) / (sum(execution_count) * 1.0) avg_physical_read
,sum(qs.total_logical_reads) total_logical_reads
,sum(qs.total_logical_reads) / (sum(execution_count) * 1.0) avg_logical_read
,sum(qs.total_logical_writes) total_logical_writes
,sum(qs.total_logical_writes) / (sum(execution_count) * 1.0) avg_logical_writes
FROM sys.dm_exec_query_stats qs CROSS APPLY sys.dm_exec_sql_text(qs.plan_handle) st
join sys.dm_exec_cached_plans cp on qs.plan_handle = cp.plan_handle
where DB_NAME(st.dbid) is not null and cp.objtype = 'proc'
group by DB_NAME(st.dbid),OBJECT_SCHEMA_NAME(objectid,st.dbid), OBJECT_NAME(objectid,st.dbid)
order by sum(qs.total_physical_reads + qs.total_logical_reads + qs.total_logical_writes) desc
Here I have displayed the total physical and logical read I/O’s, plus the logical write I/O’s. In addition, I have calculated the average number of I/O’s per execution of each SP. Physical reads are the number of reads that are actually made against the physical disk drives; where as logical reads and writes are the number of I/O’s against the cached data pages in memory in the buffer cache. Therefore, by adding the physical and logical I/O’s together I was able to calculate the total I/O’s for each SP.
To determine which SPs take the longest time to execute I can use the follow TSQL code:
SELECT DB_NAME(st.dbid) DBName
,OBJECT_SCHEMA_NAME(objectid,st.dbid) SchemaName
,OBJECT_NAME(objectid,st.dbid) StoredProcedure
,sum(execution_count) execution_count
,sum(qs.total_elapsed_time) total_elapsed_time
,sum(qs.total_elapsed_time) / sum(execution_count) avg_elapsed_time
FROM sys.dm_exec_query_stats qs CROSS APPLY sys.dm_exec_sql_text(qs.plan_handle) st
join sys.dm_exec_cached_plans cp on qs.plan_handle = cp.plan_handle
where DB_NAME(st.dbid) is not null and cp.objtype = 'proc'
group by DB_NAME(st.dbid),OBJECT_SCHEMA_NAME(objectid,st.dbid), OBJECT_NAME(objectid,st.dbid)
order by sum(qs.total_elapsed_time) descIn this TSQL, I am calculating the duration of each SP by summing up the “total_elapsed_time” in the “sys.dm_exec_sql_query_stats” DMV by database, schema and object name. I am also calculating the average elapsed time per execution of each SP. I order the output so the SP that took the longest total duration will be displayed first. If you where interested in determining the SP that had the longest average duration all you would need to change is the “ORDER BY” clause to sort by “avg_elapsed_time”.
ConclusionThe “sys.dm_exec_query_stats” SP is used to look at the accumulated statistics for cached plans. By joining the “sys.dm_exec_query_stats” view with other DMVs, you can determine other information about the cached plan, like the object type for the cached plan, and the actual name of the object. Having these DMVs in SQL Server 2005 now provides you with some data mining tools to review some performance information for a SQL Server instance. Next time you want to review statistics related to your code run on your SQL Server box consider looking at the information available in the SQL Server 2005 dynamic management views.
Execution Statistics
It is relatively easy to identify the use count and resource usage of your SP’s, but first let me discuss how SQL Server maintains the execution statistics. The SQL Server engine keeps execution statistics for each SQL Server 2005 instance. Execution Statistics are an accumulation of execution information about what has been run since the instances has started. Each time an instance is stopped and restarted all execution statistics are reset.
Individual execution statistics for an object are tied to cached execution plans. When a SP is compiled, an execution plan is cached in memory. These cached execution plans are uniquely identified by a plan_handle. Since memory is limited, SQL Server from time to time will remove execution plans from memory, if the cached plan is not being actively used. Therefore the statistics stored for a particular SP may be for an accumulation of stats since SQL Server started, if the SP has only be compiled once. Or, it may only have statistics for the last few minutes if the SP had recently been compiled.
How to Get the Execution Count of a Stored Procedure?
To determine how many times a stored procedure in the cache has been executed you need to use a couple of DMV’s and a dynamic management function (DMF). The plan_handle for the cached plans are used to join together the DMVs and retrieve records for a DMF. To get the execution counts for each cached SPs you can run the following code:
SELECT DB_NAME(st.dbid) DBName
,OBJECT_SCHEMA_NAME(st.objectid,dbid) SchemaName
,OBJECT_NAME(st.objectid,dbid) StoredProcedure
,sum(qs.execution_count) Execution_count
FROM sys.dm_exec_cached_plans
cp join sys.dm_exec_query_stats qs on cp.plan_handle = qs.plan_handle
CROSS APPLY sys.dm_exec_sql_text(cp.plan_handle) st
where DB_NAME(st.dbid) is not null and cp.objtype = 'proc'
group by DB_NAME(st.dbid),OBJECT_SCHEMA_NAME(objectid,st.dbid),
OBJECT_NAME(objectid,st.dbid)
order by sum(qs.execution_count) desc
Here I used the plan_handle of the “sys.dm_exec_cached_plans” DMV to join with the “sys.dm_exec_query_stats” DMV to obtain the “Execution_count” value where the object type is a store procedure. The “execution_count” column of the “sys.dm_exec_query_stats” DMV identifies the number of time the cached_plan (or SP) has been executed since the last compilation of the SP. I use the plan_handle in conjunction with the CROSS APPLY operator to return the object information (DBName, SchemaName, and ObjectName) using the table-value DMF “sys.dm_exec_sql_text”. The output from this SELECT statement is ordered by the execution_count, so the SP with the most executions will be displayed first.
Determining Which SP is using the Most CPU, I/O, or has the Longest Duration.
Knowing which SPs are frequently executed is useful information, although from a performance standpoint you might like to know which SP is consuming the greatest amount of CPU resources. Or possibly you might be interested in which SP takes the longest to run, or which SP performs the most physical I/O operations. By modifying the above command, we can easily answer each one of these questions.
If you want to show the SP that consumes the most CPU resources, you can run the following TSQL command:
SELECT DB_NAME(st.dbid) DBName
,OBJECT_SCHEMA_NAME(st.objectid,dbid) SchemaName
,OBJECT_NAME(st.objectid,dbid) StoredProcedure
,sum(qs.execution_count) Execution_count
,sum(qs.total_worker_time) total_cpu_time
,sum(qs.total_worker_time) / (sum(qs.execution_count) * 1.0) avg_cpu_time
FROM sys.dm_exec_cached_plans cp join sys.dm_exec_query_stats qs on cp.plan_handle = qs.plan_handle
CROSS APPLY sys.dm_exec_sql_text(cp.plan_handle) st
where DB_NAME(st.dbid) is not null and cp.objtype = 'proc'
group by DB_NAME(st.dbid),OBJECT_SCHEMA_NAME(objectid,st.dbid), OBJECT_NAME(objectid,st.dbid)
order by sum(qs.total_worker_time) desc
The “sys.dm_exec_query_stats” view contains the column “total_worker_time”, which is the total number of microseconds that a given cached query plan has executed. Keep in mind that cached plans are sometimes removed from memory and replaced with newer ones. Therefore, the statistics for which SP has consumed the most CPU only takes into account statistics for those plans that are in the cache when this T-SQL is run.
To determine which SP has executed the most I/O requests you can run the following TSQL code:
SELECT DB_NAME(st.dbid) DBName
,OBJECT_SCHEMA_NAME(objectid,st.dbid) SchemaName
,OBJECT_NAME(objectid,st.dbid) StoredProcedure
,sum(execution_count) execution_count
,sum(qs.total_physical_reads + qs.total_logical_reads + qs.total_logical_writes) total_IO
,sum(qs.total_physical_reads + qs.total_logical_reads + qs.total_logical_writes) / sum(execution_count) avg_total_IO
,sum(qs.total_physical_reads) total_physical_reads
,sum(qs.total_physical_reads) / (sum(execution_count) * 1.0) avg_physical_read
,sum(qs.total_logical_reads) total_logical_reads
,sum(qs.total_logical_reads) / (sum(execution_count) * 1.0) avg_logical_read
,sum(qs.total_logical_writes) total_logical_writes
,sum(qs.total_logical_writes) / (sum(execution_count) * 1.0) avg_logical_writes
FROM sys.dm_exec_query_stats qs CROSS APPLY sys.dm_exec_sql_text(qs.plan_handle) st
join sys.dm_exec_cached_plans cp on qs.plan_handle = cp.plan_handle
where DB_NAME(st.dbid) is not null and cp.objtype = 'proc'
group by DB_NAME(st.dbid),OBJECT_SCHEMA_NAME(objectid,st.dbid), OBJECT_NAME(objectid,st.dbid)
order by sum(qs.total_physical_reads + qs.total_logical_reads + qs.total_logical_writes) desc
Here I have displayed the total physical and logical read I/O’s, plus the logical write I/O’s. In addition, I have calculated the average number of I/O’s per execution of each SP. Physical reads are the number of reads that are actually made against the physical disk drives; where as logical reads and writes are the number of I/O’s against the cached data pages in memory in the buffer cache. Therefore, by adding the physical and logical I/O’s together I was able to calculate the total I/O’s for each SP.
To determine which SPs take the longest time to execute I can use the follow TSQL code:
SELECT DB_NAME(st.dbid) DBName
,OBJECT_SCHEMA_NAME(objectid,st.dbid) SchemaName
,OBJECT_NAME(objectid,st.dbid) StoredProcedure
,sum(execution_count) execution_count
,sum(qs.total_elapsed_time) total_elapsed_time
,sum(qs.total_elapsed_time) / sum(execution_count) avg_elapsed_time
FROM sys.dm_exec_query_stats qs CROSS APPLY sys.dm_exec_sql_text(qs.plan_handle) st
join sys.dm_exec_cached_plans cp on qs.plan_handle = cp.plan_handle
where DB_NAME(st.dbid) is not null and cp.objtype = 'proc'
group by DB_NAME(st.dbid),OBJECT_SCHEMA_NAME(objectid,st.dbid), OBJECT_NAME(objectid,st.dbid)
order by sum(qs.total_elapsed_time) descIn this TSQL, I am calculating the duration of each SP by summing up the “total_elapsed_time” in the “sys.dm_exec_sql_query_stats” DMV by database, schema and object name. I am also calculating the average elapsed time per execution of each SP. I order the output so the SP that took the longest total duration will be displayed first. If you where interested in determining the SP that had the longest average duration all you would need to change is the “ORDER BY” clause to sort by “avg_elapsed_time”.
ConclusionThe “sys.dm_exec_query_stats” SP is used to look at the accumulated statistics for cached plans. By joining the “sys.dm_exec_query_stats” view with other DMVs, you can determine other information about the cached plan, like the object type for the cached plan, and the actual name of the object. Having these DMVs in SQL Server 2005 now provides you with some data mining tools to review some performance information for a SQL Server instance. Next time you want to review statistics related to your code run on your SQL Server box consider looking at the information available in the SQL Server 2005 dynamic management views.
Saturday, June 30, 2007
What to consider when testing databases
What To Test in a Relational Database
Last month I explored the assumptions made by the traditional data management community and argued that these assumptions had been shown to be false over the years. These assumptions included the belief that you can't easily evolve a database schema, that you need to do detailed up front modeling, and that reviews and inspections are an effective way to ensure data quality. Respectively, I argued that database refactoring enables you to easily evolve database schemas, that an agile approach to data modeling is significantly more effective, and that database regression testing is the best way to ensure data quality. A debate on the Agile Databases mailing list ensued and it quickly became apparent that the traditionalists could understand, although often not accept, the first two agile database development techniques but clearly struggled with the concept of database testing. I believe that the virtual absence of discussion about testing within the data management community is the primary cause of the $611 billion annual loss, as reported by The Data Warehouse Institute, experienced by North American organizations resulting from poor data quality. So this month I've decided to describe what you should consider testing in a database.
Let's start with some terminology. Database testing is the act of validating the contents, schema, and functionality within a database. From the point of view of a relational database this includes the actual data itself, the table structures and relationships between tables, and the stored procedures/functions or database classes respectively. Database interface testing validates the database at the black-box level whereas internal database testing validates it at the clear-box level -- if any database testing occurs at all it is typically at the interface level only because of the lack of tool support for internal testing. Database regression testing is the act of running the database test suite on a regular basis, ideally whenever someone does something which could potentially inject a defect into the database such as change how they write data into a database or change some of the code within the database itself. Test Driven Database Development (TDDD), also known as "Behavior Driven Database Development" (BDDD), is the act of specifying the design of a database by writing a single test then just enough database code/schema to fulfill that test.
I think that one of the reasons why data professionals are confused about the concept of database regression testing is because it is a relatively new idea within the data community. One of the assumptions that I didn't cover last month is the idea within the traditional data community that testing is something that other people do (i.e., test or quality assurance professionals). This reflects a penchant for over-specialization and a serial approach towards development by traditionalists, two ideas which have also been shown to be questionable organizational approaches at best.
The easiest thing to get your head around is the need to validate the logic implemented within a database. Relational databases contain code, in the form of stored procedures, triggers, and even object-oriented classes. There is nothing special about this code. Just like you test application code, shouldn't you also test database code? Of course you should. You'll apply the exact same types of tests to database code as you would to application code.
What isn't as obvious, at least from the questions I was getting from traditional data professionals, was the need to validate data quality via testing. As DDJ's data quality survey showed last year, data is considered a corporate asset by 96 percent of organizations yet less than half have any sort of testing strategy in place to actually ensure data quality. In short, people like to talk about data quality but not act on it. When it comes to data you could validate the following via tests: Column domain value rules. For example, the Flavor column has allowable values of Chocolate, Vanilla, and Strawberry.
Column default value rules. For example, the default value is Strawberry.
Value existence rules. For example, there should always be a value of Flavor indicated (it can never be null).
Row value rules. For example, the value of StartDate must be less than EndDate when EndDate is provided.
Size rules. For example, a code in a column must always be two characters in length or a value in a VARCHAR column must be at least five characters in length Although these data rules can be implemented via constraints, or via other means, you still need to test to ensure that the rules are being implemented properly. Constraints can easily be dropped or reworked, therefore you should have regression tests I place to validate them. Nullability is critical to test for because a NOT NULL constraint can also easily be dropped. Furthermore, "quasi-nulls" such as empty strings are often not allowed so supporting tests should be in place to ensure this.
Table structure can also be easily validated, something that is typically done as a side effect of the tests to validate the Create Read Update and Delete (CRUD) logic of an application. These tests will break whenever you change the database schema without also changing the access code. From a database design point of view, as you write CRUD tests you are effectively designing the table structure which supports those tests.
You can also write tests which validate relationships between the rows in different tables. These tests validate referential integrity (RI) rules, for example if a row in the Employee table references a row within the Position table then that row should actually exist. RI rules such as this are typically implemented as triggers, but what happens if someone drops or modifies a trigger without understanding the implications of doing so?
You may also choose to write database performance tests to both specify performance requirements and to ensure that those requirements are met. From a black-box point of view you might write tests which validate the performance characteristics surrounding database access, including object/relational (O/R) mapping logic. From a clear-box point of view you might have tests which motivate you to maintain secondary indices to support common database access paths or to refactor your database tables into structures which are more performant.
I believe that as an industry we have a lot of work ahead of us with respect to data quality. We have known for decades that testing, particularly regression testing, leads to greater quality yet for some reason we haven't applied this knowledge to relational databases. There are many things which can and should be tested within a relational database, this column touches on just a few, and it is about time that we step up and develop new tools and techniques to do exactly that. The Agile community has lead the way to bringing regression testing, and more importantly test-first development, to application programming. This has lead to noticeable increases in quality, time to market, and return on investment (ROI). We can achieve the same successes when it comes to database design and quality.
Last month I explored the assumptions made by the traditional data management community and argued that these assumptions had been shown to be false over the years. These assumptions included the belief that you can't easily evolve a database schema, that you need to do detailed up front modeling, and that reviews and inspections are an effective way to ensure data quality. Respectively, I argued that database refactoring enables you to easily evolve database schemas, that an agile approach to data modeling is significantly more effective, and that database regression testing is the best way to ensure data quality. A debate on the Agile Databases mailing list ensued and it quickly became apparent that the traditionalists could understand, although often not accept, the first two agile database development techniques but clearly struggled with the concept of database testing. I believe that the virtual absence of discussion about testing within the data management community is the primary cause of the $611 billion annual loss, as reported by The Data Warehouse Institute, experienced by North American organizations resulting from poor data quality. So this month I've decided to describe what you should consider testing in a database.
Let's start with some terminology. Database testing is the act of validating the contents, schema, and functionality within a database. From the point of view of a relational database this includes the actual data itself, the table structures and relationships between tables, and the stored procedures/functions or database classes respectively. Database interface testing validates the database at the black-box level whereas internal database testing validates it at the clear-box level -- if any database testing occurs at all it is typically at the interface level only because of the lack of tool support for internal testing. Database regression testing is the act of running the database test suite on a regular basis, ideally whenever someone does something which could potentially inject a defect into the database such as change how they write data into a database or change some of the code within the database itself. Test Driven Database Development (TDDD), also known as "Behavior Driven Database Development" (BDDD), is the act of specifying the design of a database by writing a single test then just enough database code/schema to fulfill that test.
I think that one of the reasons why data professionals are confused about the concept of database regression testing is because it is a relatively new idea within the data community. One of the assumptions that I didn't cover last month is the idea within the traditional data community that testing is something that other people do (i.e., test or quality assurance professionals). This reflects a penchant for over-specialization and a serial approach towards development by traditionalists, two ideas which have also been shown to be questionable organizational approaches at best.
The easiest thing to get your head around is the need to validate the logic implemented within a database. Relational databases contain code, in the form of stored procedures, triggers, and even object-oriented classes. There is nothing special about this code. Just like you test application code, shouldn't you also test database code? Of course you should. You'll apply the exact same types of tests to database code as you would to application code.
What isn't as obvious, at least from the questions I was getting from traditional data professionals, was the need to validate data quality via testing. As DDJ's data quality survey showed last year, data is considered a corporate asset by 96 percent of organizations yet less than half have any sort of testing strategy in place to actually ensure data quality. In short, people like to talk about data quality but not act on it. When it comes to data you could validate the following via tests: Column domain value rules. For example, the Flavor column has allowable values of Chocolate, Vanilla, and Strawberry.
Column default value rules. For example, the default value is Strawberry.
Value existence rules. For example, there should always be a value of Flavor indicated (it can never be null).
Row value rules. For example, the value of StartDate must be less than EndDate when EndDate is provided.
Size rules. For example, a code in a column must always be two characters in length or a value in a VARCHAR column must be at least five characters in length Although these data rules can be implemented via constraints, or via other means, you still need to test to ensure that the rules are being implemented properly. Constraints can easily be dropped or reworked, therefore you should have regression tests I place to validate them. Nullability is critical to test for because a NOT NULL constraint can also easily be dropped. Furthermore, "quasi-nulls" such as empty strings are often not allowed so supporting tests should be in place to ensure this.
Table structure can also be easily validated, something that is typically done as a side effect of the tests to validate the Create Read Update and Delete (CRUD) logic of an application. These tests will break whenever you change the database schema without also changing the access code. From a database design point of view, as you write CRUD tests you are effectively designing the table structure which supports those tests.
You can also write tests which validate relationships between the rows in different tables. These tests validate referential integrity (RI) rules, for example if a row in the Employee table references a row within the Position table then that row should actually exist. RI rules such as this are typically implemented as triggers, but what happens if someone drops or modifies a trigger without understanding the implications of doing so?
You may also choose to write database performance tests to both specify performance requirements and to ensure that those requirements are met. From a black-box point of view you might write tests which validate the performance characteristics surrounding database access, including object/relational (O/R) mapping logic. From a clear-box point of view you might have tests which motivate you to maintain secondary indices to support common database access paths or to refactor your database tables into structures which are more performant.
I believe that as an industry we have a lot of work ahead of us with respect to data quality. We have known for decades that testing, particularly regression testing, leads to greater quality yet for some reason we haven't applied this knowledge to relational databases. There are many things which can and should be tested within a relational database, this column touches on just a few, and it is about time that we step up and develop new tools and techniques to do exactly that. The Agile community has lead the way to bringing regression testing, and more importantly test-first development, to application programming. This has lead to noticeable increases in quality, time to market, and return on investment (ROI). We can achieve the same successes when it comes to database design and quality.
Wednesday, June 27, 2007
Technical Blog Hello World :)
Hello everybody,
This is my technical blog, here you'll find my technical posts (as soon as I understand everything here and have the ability to write technical articles :D).
So, welcome in my technical blog and which you to enjoy your time here and be more useful for any one :)
This is my technical blog, here you'll find my technical posts (as soon as I understand everything here and have the ability to write technical articles :D).
So, welcome in my technical blog and which you to enjoy your time here and be more useful for any one :)
Subscribe to:
Posts (Atom)
Data Governance Learning Plan
Seven courses to build the knowledge of Data Governance Program ( planning & establishment ) by Kelle O'Neal with 100 MCQs Exam 1....
